2025
|
Abraham, Danny; Maity, Biswadip; Donyanavard, Bryan; Dutt, Nikil Runtime Adaptivity for Efficient Neural Network Inference on Autonomous Systems Journal Article In: ACM Trans. Embed. Comput. Syst., vol. 24, no. 6, 2025, ISSN: 1539-9087. @article{10.1145/3762640,
title = {Runtime Adaptivity for Efficient Neural Network Inference on Autonomous Systems},
author = {Danny Abraham and Biswadip Maity and Bryan Donyanavard and Nikil Dutt},
url = {https://doi.org/10.1145/3762640},
doi = {10.1145/3762640},
issn = {1539-9087},
year = {2025},
date = {2025-10-01},
urldate = {2025-10-01},
journal = {ACM Trans. Embed. Comput. Syst.},
volume = {24},
number = {6},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
abstract = {Neural network pruning and dynamic training have emerged as key techniques for optimizing deep learning models to meet the constraints of resource-limited systems. However, achieving both efficiency and adaptability without compromising safety or performance remains a significant challenge in real-time autonomous applications. We present Back to the Future and USA-Nets, two complementary approaches that address this challenge. Back to the Future combines pruning with dynamic routing to enable latency gains and dynamic reconfiguration at runtime, allowing a pruned model to seamlessly revert to the full model when unsafe or anomalous behavior is detected. USA-Nets extend this concept by enabling runtime adaptability through dynamically trained networks that can adjust their width without requiring additional annotated data or excessive storage overhead. Together, these methods deliver significant performance improvements while maintaining safety and flexibility, as evidenced by experimental results demonstrating that Back to the Future achieves a 32× faster reversion time compared to loading the full model, and USA-Nets achieve up to 85% latency reduction with minimal accuracy degradation. These innovations pave the way for efficient, adaptable, and safe deployment of deep learning models in diverse real-time and resource-constrained environments, with future work focusing on advanced pruning techniques and runtime optimizations.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Neural network pruning and dynamic training have emerged as key techniques for optimizing deep learning models to meet the constraints of resource-limited systems. However, achieving both efficiency and adaptability without compromising safety or performance remains a significant challenge in real-time autonomous applications. We present Back to the Future and USA-Nets, two complementary approaches that address this challenge. Back to the Future combines pruning with dynamic routing to enable latency gains and dynamic reconfiguration at runtime, allowing a pruned model to seamlessly revert to the full model when unsafe or anomalous behavior is detected. USA-Nets extend this concept by enabling runtime adaptability through dynamically trained networks that can adjust their width without requiring additional annotated data or excessive storage overhead. Together, these methods deliver significant performance improvements while maintaining safety and flexibility, as evidenced by experimental results demonstrating that Back to the Future achieves a 32× faster reversion time compared to loading the full model, and USA-Nets achieve up to 85% latency reduction with minimal accuracy degradation. These innovations pave the way for efficient, adaptable, and safe deployment of deep learning models in diverse real-time and resource-constrained environments, with future work focusing on advanced pruning techniques and runtime optimizations. |
Bhattacharjya, Rajat; Sarkar, Arnab; Kool, Ish; Baidya, Sabur; Dutt, Nikil ACCESS-AV: Adaptive Communication-Computation Codesign for Sustainable Autonomous Vehicle Localization in Smart Factories Journal Article In: ACM Trans. Embed. Comput. Syst., 2025, ISSN: 1539-9087, (Just Accepted). @article{10.1145/3771770,
title = {ACCESS-AV: Adaptive Communication-Computation Codesign for Sustainable Autonomous Vehicle Localization in Smart Factories},
author = {Rajat Bhattacharjya and Arnab Sarkar and Ish Kool and Sabur Baidya and Nikil Dutt},
url = {https://doi.org/10.1145/3771770},
doi = {10.1145/3771770},
issn = {1539-9087},
year = {2025},
date = {2025-10-01},
urldate = {2025-10-01},
journal = {ACM Trans. Embed. Comput. Syst.},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
abstract = {Autonomous Delivery Vehicles (ADVs) are increasingly used for transporting goods in 5G network-enabled smart factories, with the compute-intensive localization module presenting a significant opportunity for optimization. We propose ACCESS-AV, an energy-efficient Vehicle-to-Infrastructure (V2I) localization framework that leverages existing 5G infrastructure in smart factory environments. By opportunistically accessing the periodically broadcast 5G Synchronization Signal Blocks (SSBs) for localization, ACCESS-AV obviates the need for dedicated Roadside Units (RSUs) or additional onboard sensors to achieve energy efficiency as well as cost reduction. We implement an Angle-of-Arrival (AoA)-based estimation method using the Multiple Signal Classification (MUSIC) algorithm, optimized for resource-constrained ADV platforms through an adaptive communication-computation strategy that dynamically balances energy consumption with localization accuracy based on environmental conditions such as Signal-to-Noise Ratio (SNR) and vehicle velocity. Experimental results demonstrate that ACCESS-AV achieves an average energy reduction of 43.09% compared to non-adaptive systems employing AoA algorithms such as vanilla MUSIC, ESPRIT, and Root-MUSIC. It maintains sub-30 cm localization accuracy while also delivering substantial reductions in infrastructure and operational costs, establishing its viability for sustainable smart factory environments.},
note = {Just Accepted},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Autonomous Delivery Vehicles (ADVs) are increasingly used for transporting goods in 5G network-enabled smart factories, with the compute-intensive localization module presenting a significant opportunity for optimization. We propose ACCESS-AV, an energy-efficient Vehicle-to-Infrastructure (V2I) localization framework that leverages existing 5G infrastructure in smart factory environments. By opportunistically accessing the periodically broadcast 5G Synchronization Signal Blocks (SSBs) for localization, ACCESS-AV obviates the need for dedicated Roadside Units (RSUs) or additional onboard sensors to achieve energy efficiency as well as cost reduction. We implement an Angle-of-Arrival (AoA)-based estimation method using the Multiple Signal Classification (MUSIC) algorithm, optimized for resource-constrained ADV platforms through an adaptive communication-computation strategy that dynamically balances energy consumption with localization accuracy based on environmental conditions such as Signal-to-Noise Ratio (SNR) and vehicle velocity. Experimental results demonstrate that ACCESS-AV achieves an average energy reduction of 43.09% compared to non-adaptive systems employing AoA algorithms such as vanilla MUSIC, ESPRIT, and Root-MUSIC. It maintains sub-30 cm localization accuracy while also delivering substantial reductions in infrastructure and operational costs, establishing its viability for sustainable smart factory environments. |
Rebel, Alles; Dutt, Nikil; Donyanavard, Bryan OASIS: Optimized Adaptive System for Intelligent SLAM Journal Article In: ACM Trans. Embed. Comput. Syst., vol. 24, no. 5s, 2025, ISSN: 1539-9087. @article{10.1145/3761808,
title = {OASIS: Optimized Adaptive System for Intelligent SLAM},
author = {Alles Rebel and Nikil Dutt and Bryan Donyanavard},
url = {https://doi.org/10.1145/3761808},
doi = {10.1145/3761808},
issn = {1539-9087},
year = {2025},
date = {2025-09-01},
urldate = {2025-09-01},
journal = {ACM Trans. Embed. Comput. Syst.},
volume = {24},
number = {5s},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
abstract = {Visual Simultaneous Localization and Mapping (VSLAM) is essential for mobile autonomous systems operating in complex dynamic environments. VSLAM algorithms are computationally intensive and must execute in real-time on resource-constrained embedded devices. Variations in environmental complexity can lead to longer frame processing times, causing dropped frames, lost localization information, and degraded accuracy. To address these challenges, we introduce OASIS, a novel adaptive approximation method that dynamically reduces input frame areas based on real-time visual importance. Unlike traditional optimizations that require adjusting internal SLAM parameters, OASIS selectively minimizes computation by adaptively filtering less critical image regions, significantly reducing computational load. Evaluations on the EuRoC MAV dataset demonstrate that our approach balances accuracy and system predictability, achieving up to a 71.8% reduction in worst-case pose estimation errors. OASIS offers a significant advancement in reliable, predictable, and energy-efficient SLAM tailored for mobile autonomous robotic applications.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Visual Simultaneous Localization and Mapping (VSLAM) is essential for mobile autonomous systems operating in complex dynamic environments. VSLAM algorithms are computationally intensive and must execute in real-time on resource-constrained embedded devices. Variations in environmental complexity can lead to longer frame processing times, causing dropped frames, lost localization information, and degraded accuracy. To address these challenges, we introduce OASIS, a novel adaptive approximation method that dynamically reduces input frame areas based on real-time visual importance. Unlike traditional optimizations that require adjusting internal SLAM parameters, OASIS selectively minimizes computation by adaptively filtering less critical image regions, significantly reducing computational load. Evaluations on the EuRoC MAV dataset demonstrate that our approach balances accuracy and system predictability, achieving up to a 71.8% reduction in worst-case pose estimation errors. OASIS offers a significant advancement in reliable, predictable, and energy-efficient SLAM tailored for mobile autonomous robotic applications. |
Seo, Dongjoo; Sung, Changhoon; Park, Junseok; Chen, Ping-Xiang; Donyanavard, Bryan; Dutt, Nikil SPEED: Scalable and Predictable EnhancEments for Data Handling in Autonomous Systems Proceedings Article In: 2025 26th International Symposium on Quality Electronic Design (ISQED), pp. 1-7, 2025. @inproceedings{11014394,
title = {SPEED: Scalable and Predictable EnhancEments for Data Handling in Autonomous Systems},
author = {Dongjoo Seo and Changhoon Sung and Junseok Park and Ping-Xiang Chen and Bryan Donyanavard and Nikil Dutt},
doi = {10.1109/ISQED65160.2025.11014394},
year = {2025},
date = {2025-01-01},
urldate = {2025-01-01},
booktitle = {2025 26th International Symposium on Quality Electronic Design (ISQED)},
pages = {1-7},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Seo, Dongjoo; Sung, Juhee; Lee, Jaekoo; Dutt, Nikil GOLD: Green Optimization of Language Models Serving on Devices Proceedings Article In: 2025 IEEE International Conference on Consumer Electronics (ICCE), pp. 1-2, 2025. @inproceedings{10930004,
title = {GOLD: Green Optimization of Language Models Serving on Devices},
author = {Dongjoo Seo and Juhee Sung and Jaekoo Lee and Nikil Dutt},
doi = {10.1109/ICCE63647.2025.10930004},
year = {2025},
date = {2025-01-01},
urldate = {2025-01-01},
booktitle = {2025 IEEE International Conference on Consumer Electronics (ICCE)},
pages = {1-2},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
2024
|
Chen, Ping-Xiang; Seo, Dongjoo; Sung, Changhoon; Park, Jongheum; Lee, Minchul; Li, Huaicheng; Bjørling, Matias; Dutt, Nikil ZoneTrace: A Zone Monitoring Tool for F2FS on ZNS SSDs Journal Article In: ACM Trans. Des. Autom. Electron. Syst., 2024, ISSN: 1084-4309, (Just Accepted). @article{10.1145/3656172,
title = {ZoneTrace: A Zone Monitoring Tool for F2FS on ZNS SSDs},
author = {Ping-Xiang Chen and Dongjoo Seo and Changhoon Sung and Jongheum Park and Minchul Lee and Huaicheng Li and Matias Bjørling and Nikil Dutt},
url = {https://doi.org/10.1145/3656172},
doi = {10.1145/3656172},
issn = {1084-4309},
year = {2024},
date = {2024-04-01},
urldate = {2024-04-01},
journal = {ACM Trans. Des. Autom. Electron. Syst.},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
abstract = {We present ZoneTrace, a runtime monitoring tool for the Flash-Friendly File System (F2FS) on Zoned Namespace (ZNS) SSDs. ZNS SSD organizes its storage into zones of sequential write access. Due to ZNS SSD’s sequential write nature, F2FS is a log-structured file system that has recently been adopted to support ZNS SSDs. To present the space management with the zone concept between F2FS and the underlying ZNS SSD, we developed ZoneTrace, a tool that enables users to visualize and analyze the space management of F2FS on ZNS SSDs. ZoneTrace utilizes the extended Berkeley Packet Filter (eBPF) to trace the updated segment bitmap in F2FS and visualize each zone space usage accordingly. Furthermore, ZoneTrace is able to analyze on file fragmentation in F2FS and provides users with informative fragmentation histogram to serve as an indicator of file fragmentation. Using ZoneTrace’s visualization, we are able to identify the current F2FS space management scheme’s inability to fully optimize space for streaming data recording in autonomous systems, which leads to serious file fragmentation on ZNS SSDs. Our evaluations show that ZoneTrace is lightweight and assists users in getting useful insights for effortless monitoring on F2FS with ZNS SSD with both synthetic and realistic workloads. We believe ZoneTrace can help users analyze F2FS with ease and open up space management research topics with F2FS on ZNS SSDs.},
note = {Just Accepted},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
We present ZoneTrace, a runtime monitoring tool for the Flash-Friendly File System (F2FS) on Zoned Namespace (ZNS) SSDs. ZNS SSD organizes its storage into zones of sequential write access. Due to ZNS SSD’s sequential write nature, F2FS is a log-structured file system that has recently been adopted to support ZNS SSDs. To present the space management with the zone concept between F2FS and the underlying ZNS SSD, we developed ZoneTrace, a tool that enables users to visualize and analyze the space management of F2FS on ZNS SSDs. ZoneTrace utilizes the extended Berkeley Packet Filter (eBPF) to trace the updated segment bitmap in F2FS and visualize each zone space usage accordingly. Furthermore, ZoneTrace is able to analyze on file fragmentation in F2FS and provides users with informative fragmentation histogram to serve as an indicator of file fragmentation. Using ZoneTrace’s visualization, we are able to identify the current F2FS space management scheme’s inability to fully optimize space for streaming data recording in autonomous systems, which leads to serious file fragmentation on ZNS SSDs. Our evaluations show that ZoneTrace is lightweight and assists users in getting useful insights for effortless monitoring on F2FS with ZNS SSD with both synthetic and realistic workloads. We believe ZoneTrace can help users analyze F2FS with ease and open up space management research topics with F2FS on ZNS SSDs. |
Abraham, Danny; Maity, Biswadip; Donyanavard, Bryan; Dutt, Nikil Back to the Future: Reversible Runtime Neural Network Pruning for Safe Autonomous Systems Proceedings Article In: 2024 Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 1-6, 2024, ISBN: 978-3-9819263-8-5. @inproceedings{10546571,
title = {Back to the Future: Reversible Runtime Neural Network Pruning for Safe Autonomous Systems},
author = {Danny Abraham and Biswadip Maity and Bryan Donyanavard and Nikil Dutt},
isbn = {978-3-9819263-8-5},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
booktitle = {2024 Design, Automation & Test in Europe Conference & Exhibition (DATE)},
pages = {1-6},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Yi, Saehanseul; Dutt, Nikil BoostIID: Fault-agnostic Online Detection of WCET Changes in Autonomous Driving Proceedings Article In: 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), pp. 704-709, 2024. @inproceedings{10473866,
title = {BoostIID: Fault-agnostic Online Detection of WCET Changes in Autonomous Driving},
author = {Saehanseul Yi and Nikil Dutt},
doi = {10.1109/ASP-DAC58780.2024.10473866},
year = {2024},
date = {2024-01-01},
booktitle = {2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC)},
pages = {704-709},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Chen, Ping-Xiang; Seo, Dongjoo; Maity, Biswadip; Dutt, Nikil KDTree-SOM: Self-organizing Map based Anomaly Detection for Lightweight Autonomous Embedded Systems Proceedings Article In: Proceedings of the Great Lakes Symposium on VLSI 2024, pp. 700–705, Association for Computing Machinery, Clearwater, FL, USA, 2024, ISBN: 9798400706059. @inproceedings{10.1145/3649476.3658708,
title = {KDTree-SOM: Self-organizing Map based Anomaly Detection for Lightweight Autonomous Embedded Systems},
author = {Ping-Xiang Chen and Dongjoo Seo and Biswadip Maity and Nikil Dutt},
url = {https://doi.org/10.1145/3649476.3658708},
doi = {10.1145/3649476.3658708},
isbn = {9798400706059},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
booktitle = {Proceedings of the Great Lakes Symposium on VLSI 2024},
pages = {700–705},
publisher = {Association for Computing Machinery},
address = {Clearwater, FL, USA},
series = {GLSVLSI '24},
abstract = {Self-Organizing Maps (SOM) promise a lightweight approach for multivariate time series anomaly detection in lightweight autonomous embedded systems. However, the enormous volume of time series data from autonomous systems testing requires huge SOMs with impractical search overhead. We present KDTree-SOM that effectively optimizes the winner node search for huge SOMs by reconstructing the SOM as a k-dimensional tree (kd-tree). KDTree-SOM achieves on average a 4 × inference time reduction for huge SOMs while achieving up to 95% anomaly detection accuracy with only KB-level memory overhead, demonstrating its potential for anomaly detection in lightweight autonomous embedded platforms.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Self-Organizing Maps (SOM) promise a lightweight approach for multivariate time series anomaly detection in lightweight autonomous embedded systems. However, the enormous volume of time series data from autonomous systems testing requires huge SOMs with impractical search overhead. We present KDTree-SOM that effectively optimizes the winner node search for huge SOMs by reconstructing the SOM as a k-dimensional tree (kd-tree). KDTree-SOM achieves on average a 4 × inference time reduction for huge SOMs while achieving up to 95% anomaly detection accuracy with only KB-level memory overhead, demonstrating its potential for anomaly detection in lightweight autonomous embedded platforms. |
Seo, Dongjoo; Joo, Yongsoo; Dutt, Nikil Improving Virtualized I/O Performance by Expanding the Polled I/O Path of Linux Proceedings Article In: Proceedings of the 16th ACM Workshop on Hot Topics in Storage and File Systems, pp. 31–37, Association for Computing Machinery, Santa Clara, CA, USA, 2024, ISBN: 9798400706301. @inproceedings{10.1145/3655038.3665944,
title = {Improving Virtualized I/O Performance by Expanding the Polled I/O Path of Linux},
author = {Dongjoo Seo and Yongsoo Joo and Nikil Dutt},
url = {https://doi.org/10.1145/3655038.3665944},
doi = {10.1145/3655038.3665944},
isbn = {9798400706301},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
booktitle = {Proceedings of the 16th ACM Workshop on Hot Topics in Storage and File Systems},
pages = {31–37},
publisher = {Association for Computing Machinery},
address = {Santa Clara, CA, USA},
series = {HotStorage '24},
abstract = {The continuing advancement of storage technology has introduced ultra-low latency (ULL) SSDs that feature 20 μs or less access latency. Therefore, the context switching overhead of interrupts has become more pronounced on these SSDs, prompting consideration of polling as an alternative to mitigate this overhead. At the same time, the high price of ULL SSDs is a major issue preventing the wide adoption of polling.We claim that virtualized systems can benefit from polling even without ULL SSDs. Since the host page cache is located in the DRAM main memory, it can deliver even higher throughput than ULL SSDs. However, the guest operating system in virtualized environments cannot use polled I/Os when accessing the host page cache, failing to exploit the performance advantage of DRAM. To resolve this inefficiency, we propose to expand the polled I/O path of the Linux kernel I/O stack. Our approach allows guest applications to use I/O polling for buffered I/Os and memory mapped I/Os. The expanded I/O path can significantly improve the I/O performance of virtualized systems without modifying the guest application or the backend of the virtual block device. Our proposed buffered I/O path with polling improves the 4 KB random read throughput between guest applications and the host page cache by 3.2×.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
The continuing advancement of storage technology has introduced ultra-low latency (ULL) SSDs that feature 20 μs or less access latency. Therefore, the context switching overhead of interrupts has become more pronounced on these SSDs, prompting consideration of polling as an alternative to mitigate this overhead. At the same time, the high price of ULL SSDs is a major issue preventing the wide adoption of polling.We claim that virtualized systems can benefit from polling even without ULL SSDs. Since the host page cache is located in the DRAM main memory, it can deliver even higher throughput than ULL SSDs. However, the guest operating system in virtualized environments cannot use polled I/Os when accessing the host page cache, failing to exploit the performance advantage of DRAM. To resolve this inefficiency, we propose to expand the polled I/O path of the Linux kernel I/O stack. Our approach allows guest applications to use I/O polling for buffered I/Os and memory mapped I/Os. The expanded I/O path can significantly improve the I/O performance of virtualized systems without modifying the guest application or the backend of the virtual block device. Our proposed buffered I/O path with polling improves the 4 KB random read throughput between guest applications and the host page cache by 3.2×. |
Chen, Ping-Xiang; Seo, Dongjoo; Dutt, Nikil FDPFS: Leveraging File System Abstraction for FDP SSD Data Placement Journal Article In: IEEE Embedded Systems Letters, vol. 16, no. 4, pp. 349-352, 2024. @article{10779575,
title = {FDPFS: Leveraging File System Abstraction for FDP SSD Data Placement},
author = {Ping-Xiang Chen and Dongjoo Seo and Nikil Dutt},
doi = {10.1109/LES.2024.3443205},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
journal = {IEEE Embedded Systems Letters},
volume = {16},
number = {4},
pages = {349-352},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Bhattacharjya, Rajat; Sarkar, Arnab; Maity, Biswadip; Dutt, Nikil MUSIC-Lite: Efficient MUSIC Using Approximate Computing: An OFDM Radar Case Study Journal Article In: IEEE Embedded Systems Letters, vol. 16, no. 4, pp. 329-332, 2024. @article{10779970,
title = {MUSIC-Lite: Efficient MUSIC Using Approximate Computing: An OFDM Radar Case Study},
author = {Rajat Bhattacharjya and Arnab Sarkar and Biswadip Maity and Nikil Dutt},
doi = {10.1109/LES.2024.3440208},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
journal = {IEEE Embedded Systems Letters},
volume = {16},
number = {4},
pages = {329-332},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Alikhani, Hamidreza; Kanduri, Anil; Liljeberg, Pasi; Rahmani, Amir M.; Dutt, Nikil Work-in-Progress: Context and Noise Aware Resilience for Autonomous Driving Applications Proceedings Article In: 2024 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ISSS), pp. 6-6, 2024. @inproceedings{10740731,
title = {Work-in-Progress: Context and Noise Aware Resilience for Autonomous Driving Applications},
author = {Hamidreza Alikhani and Anil Kanduri and Pasi Liljeberg and Amir M. Rahmani and Nikil Dutt},
doi = {10.1109/CODES-ISSS60120.2024.00010},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
booktitle = {2024 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ISSS)},
pages = {6-6},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Alikhani, Hamidreza; Kanduri, Anil; Naeini, Emad Kasaeyan; Shahhosseini, Sina; Liljeberg, Pasi; Rahmani, Amir M.; Dutt, Nikil ISCA: Intelligent Sense-Compute Adaptive Co-optimization of Multimodal Machine Learning Kernels for Resilient mHealth Services on Wearables Journal Article In: IEEE Design & Test, pp. 1-1, 2024. @article{10697219,
title = {ISCA: Intelligent Sense-Compute Adaptive Co-optimization of Multimodal Machine Learning Kernels for Resilient mHealth Services on Wearables},
author = {Hamidreza Alikhani and Anil Kanduri and Emad Kasaeyan Naeini and Sina Shahhosseini and Pasi Liljeberg and Amir M. Rahmani and Nikil Dutt},
doi = {10.1109/MDAT.2024.3469828},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
journal = {IEEE Design & Test},
pages = {1-1},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
2023
|
Yi, Saehanseul; Kim, Tae-Wook; Kim, Jong-Chan; Dutt, Nikil EASYR: Energy-Efficient Adaptive System Reconfiguration for Dynamic Deadlines in Autonomous Driving on Multicore Processors Journal Article In: ACM Trans. Embed. Comput. Syst., vol. 22, no. 3, 2023, ISSN: 1539-9087. @article{10.1145/3570503,
title = {EASYR: Energy-Efficient Adaptive System Reconfiguration for Dynamic Deadlines in Autonomous Driving on Multicore Processors},
author = {Saehanseul Yi and Tae-Wook Kim and Jong-Chan Kim and Nikil Dutt},
url = {https://doi.org/10.1145/3570503},
doi = {10.1145/3570503},
issn = {1539-9087},
year = {2023},
date = {2023-04-01},
journal = {ACM Trans. Embed. Comput. Syst.},
volume = {22},
number = {3},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
abstract = {The increasing computing demands of autonomous driving applications have driven the adoption of multicore processors in real-time systems, which in turn renders energy optimizations critical for reducing battery capacity and vehicle weight. A typical energy optimization method targeting traditional real-time systems finds a critical speed under a static deadline, resulting in conservative energy savings that are unable to exploit dynamic changes in the system and environment. We capture emerging dynamic deadlines arising from the vehicle’s change in velocity and driving context for an additional energy optimization opportunity. In this article, we extend the preliminary work for uniprocessors [66] to multicore processors, which introduces several challenges. We use the state-of-the-art real-time gang scheduling [5] to mitigate some of the challenges. However, it entails an NP-hard combinatorial problem in that tasks need to be grouped into gangs of tasks, gang formation, which could significantly affect the energy saving result. As such, we present EASYR, an adaptive system optimization and reconfiguration approach that generates gangs of tasks from a given directed acyclic graph for multicore processors and dynamically adapts the scheduling parameters and processor speeds to satisfy dynamic deadlines while consuming as little energy as possible. The timing constraints are also satisfied between system reconfigurations through our proposed safe mode change protocol. Our extensive experiments with randomly generated task graphs show that our gang formation heuristic performs 32% better than the state-of-the-art one. Using an autonomous driving task set from Bosch and real-world driving data, our experiments show that EASYR achieves energy reductions of up to 30.3% on average in typical driving scenarios compared with a conventional energy optimization method with the current state-of-the-art gang formation heuristic in real-time systems, demonstrating great potential for dynamic energy optimization gains by exploiting dynamic deadlines.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
The increasing computing demands of autonomous driving applications have driven the adoption of multicore processors in real-time systems, which in turn renders energy optimizations critical for reducing battery capacity and vehicle weight. A typical energy optimization method targeting traditional real-time systems finds a critical speed under a static deadline, resulting in conservative energy savings that are unable to exploit dynamic changes in the system and environment. We capture emerging dynamic deadlines arising from the vehicle’s change in velocity and driving context for an additional energy optimization opportunity. In this article, we extend the preliminary work for uniprocessors [66] to multicore processors, which introduces several challenges. We use the state-of-the-art real-time gang scheduling [5] to mitigate some of the challenges. However, it entails an NP-hard combinatorial problem in that tasks need to be grouped into gangs of tasks, gang formation, which could significantly affect the energy saving result. As such, we present EASYR, an adaptive system optimization and reconfiguration approach that generates gangs of tasks from a given directed acyclic graph for multicore processors and dynamically adapts the scheduling parameters and processor speeds to satisfy dynamic deadlines while consuming as little energy as possible. The timing constraints are also satisfied between system reconfigurations through our proposed safe mode change protocol. Our extensive experiments with randomly generated task graphs show that our gang formation heuristic performs 32% better than the state-of-the-art one. Using an autonomous driving task set from Bosch and real-world driving data, our experiments show that EASYR achieves energy reductions of up to 30.3% on average in typical driving scenarios compared with a conventional energy optimization method with the current state-of-the-art gang formation heuristic in real-time systems, demonstrating great potential for dynamic energy optimization gains by exploiting dynamic deadlines. |
Melo, Caio Batista De; Ashrafiamiri, Marzieh; Seo, Minjun; Kurdahi, Fadi; Dutt, Nikil SAFER: Safety Assurances For Emergent Behavior Journal Article In: IEEE Design & Test, pp. 1-1, 2023. @article{10286166,
title = {SAFER: Safety Assurances For Emergent Behavior},
author = {Caio Batista De Melo and Marzieh Ashrafiamiri and Minjun Seo and Fadi Kurdahi and Nikil Dutt},
doi = {10.1109/MDAT.2023.3324887},
year = {2023},
date = {2023-01-01},
journal = {IEEE Design & Test},
pages = {1-1},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Alikhani, Hamidreza; Kanduri, Anil; Liljeberg, Pasi; Rahmani, Amir M; Dutt, Nikil DynaFuse: Dynamic Fusion for Resource Efficient Multi-Modal Machine Learning Inference Conference 2023, ISSN: 1943-0671. @conference{10261977,
title = {DynaFuse: Dynamic Fusion for Resource Efficient Multi-Modal Machine Learning Inference},
author = {Hamidreza Alikhani and Anil Kanduri and Pasi Liljeberg and Amir M Rahmani and Nikil Dutt},
doi = {10.1109/LES.2023.3298738},
issn = {1943-0671},
year = {2023},
date = {2023-01-01},
journal = {IEEE Embedded Systems Letters},
pages = {1-1},
abstract = {Multi-modal machine learning (MMML) applications combine results from different modalities in the inference phase to improve prediction accuracy. Existing MMML fusion strategies use static modality weight assignment, based on the intrinsic value of sensor modalities determined during the training phase. However, input data perturbations in practical scenarios affect the intrinsic value of modalities in the inference phase, lowering prediction accuracy, and draining computational and energy resources. In this work, we present DynaFuse, a framework for dynamic and adaptive fusion of MMML inference to set modality weights, considering run-time parameters of input data quality and sensor energy budgets. We determine the insightfulness of modalities by combining design-time intrinsic value with the run-time extrinsic value of different modalities to assign updated modality weights, catering to both accuracy requirements and energy conservation demands. The DynaFuse approach achieves up to 22% gain in prediction accuracy and an average energy savings of 34% on exemplary MMML applications of human activity recognition and stress monitoring in comparison with state-of-the-art static fusion approaches.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Multi-modal machine learning (MMML) applications combine results from different modalities in the inference phase to improve prediction accuracy. Existing MMML fusion strategies use static modality weight assignment, based on the intrinsic value of sensor modalities determined during the training phase. However, input data perturbations in practical scenarios affect the intrinsic value of modalities in the inference phase, lowering prediction accuracy, and draining computational and energy resources. In this work, we present DynaFuse, a framework for dynamic and adaptive fusion of MMML inference to set modality weights, considering run-time parameters of input data quality and sensor energy budgets. We determine the insightfulness of modalities by combining design-time intrinsic value with the run-time extrinsic value of different modalities to assign updated modality weights, catering to both accuracy requirements and energy conservation demands. The DynaFuse approach achieves up to 22% gain in prediction accuracy and an average energy savings of 34% on exemplary MMML applications of human activity recognition and stress monitoring in comparison with state-of-the-art static fusion approaches. |
de Melo, Caio Batista; Dutt, Nikil LOCoCAT: Low-Overhead Classification of CAN Bus Attack Types Conference 2023. @conference{10261979,
title = {LOCoCAT: Low-Overhead Classification of CAN Bus Attack Types},
author = {Caio Batista de Melo and Nikil Dutt},
doi = {10.1109/LES.2023.3299217},
year = {2023},
date = {2023-01-01},
journal = {IEEE Embedded Systems Letters},
pages = {1-1},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
|
Seo, Dongjoo; Chen, Ping-Xiang; Li, Huaicheng; Bjørling, Matias; Dutt, Nikil Is Garbage Collection Overhead Gone? Case Study of F2FS on ZNS SSDs Proceedings Article In: Proceedings of the 15th ACM Workshop on Hot Topics in Storage and File Systems, pp. 102–108, Association for Computing Machinery, Boston, MA, USA, 2023, ISBN: 9798400702242. @inproceedings{10.1145/3599691.3603409,
title = {Is Garbage Collection Overhead Gone? Case Study of F2FS on ZNS SSDs},
author = {Dongjoo Seo and Ping-Xiang Chen and Huaicheng Li and Matias Bjø{}rling and Nikil Dutt},
url = {https://doi.org/10.1145/3599691.3603409},
doi = {10.1145/3599691.3603409},
isbn = {9798400702242},
year = {2023},
date = {2023-01-01},
booktitle = {Proceedings of the 15th ACM Workshop on Hot Topics in Storage and File Systems},
pages = {102–108},
publisher = {Association for Computing Machinery},
address = {Boston, MA, USA},
series = {HotStorage '23},
abstract = {The sequential write nature of ZNS SSDs makes them very well-suited for log-structured file systems. The Flash-Friendly File System (F2FS), is one such log-structured file system and has recently gained support for use with ZNS SSDs. The large F2FS over-provisioning space for ZNS SSDs greatly reduces the garbage collection (GC) overhead in the log-structured file systems. Motivated by this observation, we explore the trade-off between disk utilization and over-provisioning space, which affects the garbage collection process, as well as the user application performance. To address the performance degradation in write-intensive workloads caused by GC overhead, we propose a modified free segment-finding policy and a Parallel Garbage Collection (P-GC) scheme for F2FS that efficiently reduces GC overhead. Our evaluation results demonstrate that our P-GC scheme can achieve up to 42% performance enhancement with various workloads.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
The sequential write nature of ZNS SSDs makes them very well-suited for log-structured file systems. The Flash-Friendly File System (F2FS), is one such log-structured file system and has recently gained support for use with ZNS SSDs. The large F2FS over-provisioning space for ZNS SSDs greatly reduces the garbage collection (GC) overhead in the log-structured file systems. Motivated by this observation, we explore the trade-off between disk utilization and over-provisioning space, which affects the garbage collection process, as well as the user application performance. To address the performance degradation in write-intensive workloads caused by GC overhead, we propose a modified free segment-finding policy and a Parallel Garbage Collection (P-GC) scheme for F2FS that efficiently reduces GC overhead. Our evaluation results demonstrate that our P-GC scheme can achieve up to 42% performance enhancement with various workloads. |
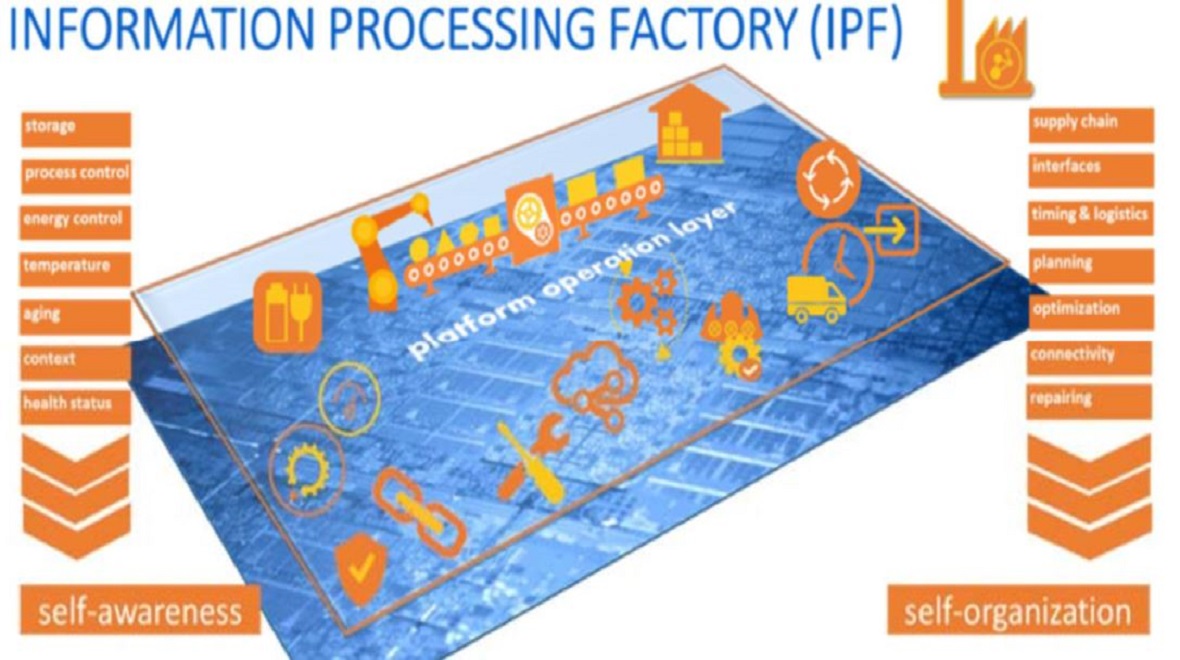
Sperling, Nora; Bendrick, Alex; Stöhrmann, Dominik; Ernst, Rolf; Donyanavard, Bryan; Maurer, Florian; Lenke, Oliver; Surhonne, Anmol; Herkersdorf, Andreas; Amer, Walaa; de Melo, Caio Batista; Chen, Ping-Xiang; Hoang, Quang Anh; Karami, Rachid; Maity, Biswadip; Nikolian, Paul; Rakka, Mariam; Seo, Dongjoo; Yi, Saehanseul; Seo, Minjun; Dutt, Nikil; Kurdahi, Fadi Information Processing Factory 2.0 - Self-awareness for Autonomous Collaborative Systems Proceedings Article In: 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 1-6, 2023. @inproceedings{10137006,
title = {Information Processing Factory 2.0 - Self-awareness for Autonomous Collaborative Systems},
author = {Nora Sperling and Alex Bendrick and Dominik Stöhrmann and Rolf Ernst and Bryan Donyanavard and Florian Maurer and Oliver Lenke and Anmol Surhonne and Andreas Herkersdorf and Walaa Amer and Caio Batista de Melo and Ping-Xiang Chen and Quang Anh Hoang and Rachid Karami and Biswadip Maity and Paul Nikolian and Mariam Rakka and Dongjoo Seo and Saehanseul Yi and Minjun Seo and Nikil Dutt and Fadi Kurdahi},
doi = {10.23919/DATE56975.2023.10137006},
year = {2023},
date = {2023-01-01},
booktitle = {2023 Design, Automation & Test in Europe Conference & Exhibition (DATE)},
pages = {1-6},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
2022
|
Ji, Mingoo; Yi, Saehanseul; Koo, Changjin; Ahn, Sol; Seo, Dongjoo; Dutt, Nikil; Kim, Jong-Chan Demand Layering for Real-Time DNN Inference with Minimized Memory Usage Proceedings Article In: 2022 IEEE Real-Time Systems Symposium (RTSS), pp. 291-304, 2022. @inproceedings{9984745,
title = {Demand Layering for Real-Time DNN Inference with Minimized Memory Usage},
author = {Mingoo Ji and Saehanseul Yi and Changjin Koo and Sol Ahn and Dongjoo Seo and Nikil Dutt and Jong-Chan Kim},
doi = {10.1109/RTSS55097.2022.00033},
year = {2022},
date = {2022-12-26},
booktitle = {2022 IEEE Real-Time Systems Symposium (RTSS)},
pages = {291-304},
abstract = {When executing a deep neural network (DNN), its model parameters are loaded into GPU memory before execution, incurring a significant GPU memory burden. There are studies that reduce GPU memory usage by exploiting CPU memory as a swap device. However, this approach is not applicable in most embedded systems with integrated GPUs where CPU and GPU share a common memory. In this regard, we present Demand Layering, which employs a fast solid-state drive (SSD) as a co-running partner of a GPU and exploits the layer-by-layer execution of DNNs. In our approach, a DNN is loaded and executed in a layer-by-layer manner, minimizing the memory usage to the order of a single layer. Also, we developed a pipeline architecture that hides most additional delays caused by the interleaved parameter loadings alongside layer executions. Our implementation shows a 96.5% memory reduction with just 14.8% delay overhead on average for representative DNNs. Furthermore, by exploiting the memory-delay tradeoff, near-zero delay overhead (under 1 ms) can be achieved with a slightly increased memory usage (still an 88.4% reduction), showing the great potential of Demand Layering.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
When executing a deep neural network (DNN), its model parameters are loaded into GPU memory before execution, incurring a significant GPU memory burden. There are studies that reduce GPU memory usage by exploiting CPU memory as a swap device. However, this approach is not applicable in most embedded systems with integrated GPUs where CPU and GPU share a common memory. In this regard, we present Demand Layering, which employs a fast solid-state drive (SSD) as a co-running partner of a GPU and exploits the layer-by-layer execution of DNNs. In our approach, a DNN is loaded and executed in a layer-by-layer manner, minimizing the memory usage to the order of a single layer. Also, we developed a pipeline architecture that hides most additional delays caused by the interleaved parameter loadings alongside layer executions. Our implementation shows a 96.5% memory reduction with just 14.8% delay overhead on average for representative DNNs. Furthermore, by exploiting the memory-delay tradeoff, near-zero delay overhead (under 1 ms) can be achieved with a slightly increased memory usage (still an 88.4% reduction), showing the great potential of Demand Layering. |
Seo, Dongjoo; Maity, Biswadip; Chen, Ping-Xiang; Yun, Dukyoung; Donyanavard, Bryan; Dutt, Nikil ProSwap: Period-aware Proactive Swapping to Maximize Embedded Application Performance Proceedings Article In: 2022 IEEE International Conference on Networking, Architecture and Storage (NAS), pp. 1-4, 2022. @inproceedings{9925330,
title = {ProSwap: Period-aware Proactive Swapping to Maximize Embedded Application Performance},
author = {Dongjoo Seo and Biswadip Maity and Ping-Xiang Chen and Dukyoung Yun and Bryan Donyanavard and Nikil Dutt},
url = {https://ieeexplore.ieee.org/document/9925330},
doi = {10.1109/NAS55553.2022.9925330},
year = {2022},
date = {2022-11-03},
booktitle = {2022 IEEE International Conference on Networking, Architecture and Storage (NAS)},
pages = {1-4},
abstract = {Linux prevents errors due to physical memory limits by swapping out active application memory from main memory to secondary storage. Swapping degrades application performance due to swap-in/out latency overhead. To mitigate the swapping overhead in periodic applications, we present ProSwap: a period-aware proactive and adaptive swapping policy for embedded systems. ProSwap exploits application periodic behavior to proactively swap-out rarely-used physical memory pages, creating more space for active processes. A flexible memory reclamation time window enables adaptation to memory limitations that vary between applications. We demonstrate ProSwap's efficacy for an autonomous vehicle application scenario executing multi-application pipelines and show that our policy achieves up to 1.26×performance gain via proactive swapping.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Linux prevents errors due to physical memory limits by swapping out active application memory from main memory to secondary storage. Swapping degrades application performance due to swap-in/out latency overhead. To mitigate the swapping overhead in periodic applications, we present ProSwap: a period-aware proactive and adaptive swapping policy for embedded systems. ProSwap exploits application periodic behavior to proactively swap-out rarely-used physical memory pages, creating more space for active processes. A flexible memory reclamation time window enables adaptation to memory limitations that vary between applications. We demonstrate ProSwap's efficacy for an autonomous vehicle application scenario executing multi-application pipelines and show that our policy achieves up to 1.26×performance gain via proactive swapping. |
Shahhosseini, Sina; Anzanpour, Arman; Azimi, Iman; Labbaf, Sina; Seo, DongJoo; Lim, Sung-Soo; Liljeberg, Pasi; Dutt, Nikil; Rahmani, Amir M Exploring computation offloading in IoT systems Journal Article In: Information Systems, vol. 107, 2022, ISSN: 0306-4379. @article{Shahhosseini2022,
title = {Exploring computation offloading in IoT systems},
author = {Sina Shahhosseini and Arman Anzanpour and Iman Azimi and Sina Labbaf and DongJoo Seo and Sung-Soo Lim and Pasi Liljeberg and Nikil Dutt and Amir M Rahmani },
url = {https://www.sciencedirect.com/science/article/pii/S0306437921000910?via%3Dihub},
issn = {0306-4379},
year = {2022},
date = {2022-07-01},
journal = {Information Systems},
volume = {107},
abstract = {Internet of Things (IoT) paradigm raises challenges for devising efficient strategies that offload
applications to the fog or the cloud layer while ensuring the optimal response time for a ser-
vice. Traditional computation offloading policies assume the response time is only dominated by
the execution time. However, the response time is a function of many factors including contextual
parameters and application characteristics that can change over time. For the computation offloading
problem, the majority of existing literature presents efficient solutions considering a limited number of
parameters (e.g., computation capacity and network bandwidth) neglecting the effect of the application
characteristics and dataflow configuration. In this paper, we explore the impact of the computation
offloading on total application response time in three-layer IoT systems considering more realistic
parameters, e.g., application characteristics, system complexity, communication cost, and dataflow
configuration. This paper also highlights the impact of a new application characteristic parameter
defined as Output–Input Data Generation (OIDG) ratio and dataflow configuration on the system
behavior. In addition, we present a proof-of-concept end-to-end dynamic computation offloading
technique, implemented in a real hardware setup, that observes the aforementioned parameters to
perform real-time decision-making.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Internet of Things (IoT) paradigm raises challenges for devising efficient strategies that offload
applications to the fog or the cloud layer while ensuring the optimal response time for a ser-
vice. Traditional computation offloading policies assume the response time is only dominated by
the execution time. However, the response time is a function of many factors including contextual
parameters and application characteristics that can change over time. For the computation offloading
problem, the majority of existing literature presents efficient solutions considering a limited number of
parameters (e.g., computation capacity and network bandwidth) neglecting the effect of the application
characteristics and dataflow configuration. In this paper, we explore the impact of the computation
offloading on total application response time in three-layer IoT systems considering more realistic
parameters, e.g., application characteristics, system complexity, communication cost, and dataflow
configuration. This paper also highlights the impact of a new application characteristic parameter
defined as Output–Input Data Generation (OIDG) ratio and dataflow configuration on the system
behavior. In addition, we present a proof-of-concept end-to-end dynamic computation offloading
technique, implemented in a real hardware setup, that observes the aforementioned parameters to
perform real-time decision-making. |
Shahhosseini, Sina; Hu, Tianyi; Seo, Dongjoo; Kanduri, Anil; Donyanavard, Bryan; Rahmani, Amir M; Dutt, Nikil Hybrid Learning for Orchestrating Deep Learning Inference in Multi-user Edge-cloud Networks (Best Paper Award) Proceedings Article In: 2022 23rd International Symposium on Quality Electronic Design (ISQED), pp. 1-6, 2022. @inproceedings{9806291,
title = {Hybrid Learning for Orchestrating Deep Learning Inference in Multi-user Edge-cloud Networks (Best Paper Award)},
author = {Sina Shahhosseini and Tianyi Hu and Dongjoo Seo and Anil Kanduri and Bryan Donyanavard and Amir M Rahmani and Nikil Dutt},
url = {https://ieeexplore.ieee.org/document/9806291},
doi = {10.1109/ISQED54688.2022.9806291},
year = {2022},
date = {2022-06-29},
booktitle = {2022 23rd International Symposium on Quality Electronic Design (ISQED)},
pages = {1-6},
abstract = {Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). Identifying optimal orchestration considering the cross-layer opportunities and requirements in the face of varying system dynamics is a challenging multi-dimensional problem. While Reinforcement Learning (RL) approaches have been proposed earlier, they suffer from a large number of trial-and-errors during the learning process resulting in excessive time and resource consumption. We present a Hybrid Learning orchestration framework that reduces the number of interactions with the system environment by combining model-based and model-free reinforcement learning. Our Deep Learning inference orchestration strategy employs reinforcement learning to find the optimal orchestration policy. Furthermore, we deploy Hybrid Learning (HL) to accelerate the RL learning process and reduce the number of direct samplings. We demonstrate efficacy of our HL strategy through experimental comparison with state-of-the-art RL-based inference orchestration, demonstrating that our HL strategy accelerates the learning process by up to 166.6×.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). Identifying optimal orchestration considering the cross-layer opportunities and requirements in the face of varying system dynamics is a challenging multi-dimensional problem. While Reinforcement Learning (RL) approaches have been proposed earlier, they suffer from a large number of trial-and-errors during the learning process resulting in excessive time and resource consumption. We present a Hybrid Learning orchestration framework that reduces the number of interactions with the system environment by combining model-based and model-free reinforcement learning. Our Deep Learning inference orchestration strategy employs reinforcement learning to find the optimal orchestration policy. Furthermore, we deploy Hybrid Learning (HL) to accelerate the RL learning process and reduce the number of direct samplings. We demonstrate efficacy of our HL strategy through experimental comparison with state-of-the-art RL-based inference orchestration, demonstrating that our HL strategy accelerates the learning process by up to 166.6×. |
Shahhosseini, Sina; Seo, Dongjoo; Kanduri, Anil; Hu, Tianyi; Lim, Sung-Soo; Donyanavard, Bryan; Rahmani, Amir M.; Dutt, Nikil D. Online Learning for Orchestration of Inference in Multi-User End-Edge-Cloud Networks Journal Article In: ACM Transactions on Embedded Computing Systems (TECS), 2022, ISSN: 1539-9087. @article{https://doi.org/10.1145/3520129,
title = {Online Learning for Orchestration of Inference in Multi-User End-Edge-Cloud Networks},
author = {Sina Shahhosseini and Dongjoo Seo and Anil Kanduri and Tianyi Hu and Sung-Soo Lim and Bryan Donyanavard and Amir M. Rahmani and Nikil D. Dutt},
url = {https://dl.acm.org/doi/abs/10.1145/3520129},
doi = {10.1145/3520129},
issn = {1539-9087},
year = {2022},
date = {2022-02-21},
journal = {ACM Transactions on Embedded Computing Systems (TECS)},
abstract = {Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Deploying deep-learning-based intelligence near the end-user enhances privacy protection, responsiveness, and reliability. Resource-constrained end-devices must be carefully managed in order to meet the latency and energy requirements of computationally-intensive deep learning services. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). On the other hand, deep learning model optimization provides another source of tradeoff between latency and model accuracy. An end-to-end decision-making solution that considers such computation-communication problem is required to synergistically find the optimal offloading policy and model for deep learning services. To this end, we propose a reinforcement-learning-based computation offloading solution that learns optimal offloading policy considering deep learning model selection techniques to minimize response time while providing sufficient accuracy. We demonstrate the effectiveness of our solution for edge devices in an end-edge-cloud system and evaluate with a real-setup implementation using multiple AWS and ARM core configurations. Our solution provides 35% speedup in the average response time compared to the state-of-the-art with less than 0.9% accuracy reduction, demonstrating the promise of our online learning framework for orchestrating DL inference in end-edge-cloud systems.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Deploying deep-learning-based intelligence near the end-user enhances privacy protection, responsiveness, and reliability. Resource-constrained end-devices must be carefully managed in order to meet the latency and energy requirements of computationally-intensive deep learning services. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). On the other hand, deep learning model optimization provides another source of tradeoff between latency and model accuracy. An end-to-end decision-making solution that considers such computation-communication problem is required to synergistically find the optimal offloading policy and model for deep learning services. To this end, we propose a reinforcement-learning-based computation offloading solution that learns optimal offloading policy considering deep learning model selection techniques to minimize response time while providing sufficient accuracy. We demonstrate the effectiveness of our solution for edge devices in an end-edge-cloud system and evaluate with a real-setup implementation using multiple AWS and ARM core configurations. Our solution provides 35% speedup in the average response time compared to the state-of-the-art with less than 0.9% accuracy reduction, demonstrating the promise of our online learning framework for orchestrating DL inference in end-edge-cloud systems. |
2021
|
Yi, Saehanseul; Kim, Tae-Wook; Kim, Jong-Chan; Dutt, Nikil D Energy-Efficient Adaptive System Reconfiguration for Dynamic Deadlines in Autonomous Driving Proceedings Article In: 24th IEEE International Symposium on Real-Time Distributed Computing,
ISORC 2021, Daegu, South Korea, June 1-3, 2021, pp. 96–104, IEEE, 2021. @inproceedings{DBLP:conf/isorc/YiKKD21,
title = {Energy-Efficient Adaptive System Reconfiguration for Dynamic Deadlines in Autonomous Driving},
author = {Saehanseul Yi and Tae-Wook Kim and Jong-Chan Kim and Nikil D Dutt},
url = {https://doi.org/10.1109/ISORC52013.2021.00023},
doi = {10.1109/ISORC52013.2021.00023},
year = {2021},
date = {2021-01-01},
booktitle = {24th IEEE International Symposium on Real-Time Distributed Computing,
ISORC 2021, Daegu, South Korea, June 1-3, 2021},
pages = {96--104},
publisher = {IEEE},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Maity, Biswadip; Donyanavard, Bryan; Surhonne, Anmol; Rahmani, Amir M; Herkersdorf, Andreas; Dutt, Nikil D SEAMS: Self-Optimizing Runtime Manager for Approximate Memory Hierarchies Journal Article In: ACM Trans. Embed. Comput. Syst., vol. 20, no. 5, pp. 48:1–48:26, 2021. @article{DBLP:journals/tecs/MaityDSRHD21,
title = {SEAMS: Self-Optimizing Runtime Manager for Approximate Memory Hierarchies},
author = {Biswadip Maity and Bryan Donyanavard and Anmol Surhonne and Amir M Rahmani and Andreas Herkersdorf and Nikil D Dutt},
url = {https://doi.org/10.1145/3466875},
doi = {10.1145/3466875},
year = {2021},
date = {2021-01-01},
journal = {ACM Trans. Embed. Comput. Syst.},
volume = {20},
number = {5},
pages = {48:1--48:26},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Donyanavard, Bryan; ü, Tiago M; Moazzemi, Kasra; Maity, Biswadip; de Melo, Caio Batista; Stewart, Kenneth; Yi, Saehanseul; Rahmani, Amir M; Dutt, Nikil D Reflecting on Self-Aware Systems-on-Chip Proceedings Article In: A Journey of Embedded and Cyber-Physical Systems - Essays Dedicated
to Peter Marwedel on the Occasion of His 70th Birthday, pp. 79–95, Springer, 2021. @inproceedings{DBLP:conf/birthday/DonyanavardMMMM21,
title = {Reflecting on Self-Aware Systems-on-Chip},
author = {Bryan Donyanavard and Tiago M ü and Kasra Moazzemi and Biswadip Maity and Caio Batista de Melo and Kenneth Stewart and Saehanseul Yi and Amir M Rahmani and Nikil D Dutt},
url = {https://doi.org/10.1007/978-3-030-47487-4_6},
doi = {10.1007/978-3-030-47487-4_6},
year = {2021},
date = {2021-01-01},
booktitle = {A Journey of Embedded and Cyber-Physical Systems - Essays Dedicated
to Peter Marwedel on the Occasion of His 70th Birthday},
pages = {79--95},
publisher = {Springer},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Mück, Tiago; Donyanavard, Bryan; Maity, Biswadip; Moazzemi, Kasra; Dutt, Nikil D MARS: Middleware for Adaptive Reflective Computer Systems Journal Article In: CoRR, vol. abs/2107.11417, 2021. @article{DBLP:journals/corr/abs-2107-11417,
title = {MARS: Middleware for Adaptive Reflective Computer Systems},
author = {Tiago Mück and Bryan Donyanavard and Biswadip Maity and Kasra Moazzemi and Nikil D Dutt},
url = {https://arxiv.org/abs/2107.11417},
year = {2021},
date = {2021-01-01},
journal = {CoRR},
volume = {abs/2107.11417},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
2020
|
Seo, Dongjoo; Shahhosseini, Sina; Mehrabadi, Milad Asgari; Donyanavard, Bryan; Lim, Sung-Soo; Rahmani, Amir M; Dutt, Nikil D Dynamic iFogSim: A Framework for Full-Stack Simulation of Dynamic Resource Management in IoT Systems Proceedings Article In: 2020 International Conference on Omni-layer Intelligent Systems, COINS
2020, Barcelona, Spain, August 31 - September 2, 2020, pp. 1–6, IEEE, 2020. @inproceedings{DBLP:conf/coins/SeoSMDLRD20,
title = {Dynamic iFogSim: A Framework for Full-Stack Simulation of Dynamic Resource Management in IoT Systems},
author = {Dongjoo Seo and Sina Shahhosseini and Milad Asgari Mehrabadi and Bryan Donyanavard and Sung-Soo Lim and Amir M Rahmani and Nikil D Dutt},
url = {https://doi.org/10.1109/COINS49042.2020.9191663},
doi = {10.1109/COINS49042.2020.9191663},
year = {2020},
date = {2020-01-01},
booktitle = {2020 International Conference on Omni-layer Intelligent Systems, COINS
2020, Barcelona, Spain, August 31 - September 2, 2020},
pages = {1--6},
publisher = {IEEE},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Maity, Biswadip; Shoushtari, Majid; Rahmani, Amir M; Dutt, Nikil D Self-Adaptive Memory Approximation: A Formal Control Theory Approach Journal Article In: IEEE Embed. Syst. Lett., vol. 12, no. 2, pp. 33–36, 2020. @article{DBLP:journals/esl/MaitySRD20,
title = {Self-Adaptive Memory Approximation: A Formal Control Theory Approach},
author = {Biswadip Maity and Majid Shoushtari and Amir M Rahmani and Nikil D Dutt},
url = {https://doi.org/10.1109/LES.2019.2941018},
doi = {10.1109/LES.2019.2941018},
year = {2020},
date = {2020-01-01},
journal = {IEEE Embed. Syst. Lett.},
volume = {12},
number = {2},
pages = {33--36},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Bellman, Kirstie L; Landauer, Christopher; Dutt, Nikil D; Esterle, Lukas; Herkersdorf, Andreas; Jantsch, Axel; Taherinejad, Nima; Lewis, Peter R; Platzner, Marco; ä, Kalle Tammem Self-aware Cyber-Physical Systems Journal Article In: ACM Trans. Cyber Phys. Syst., vol. 4, no. 4, pp. 38:1–38:26, 2020. @article{DBLP:journals/tcps/BellmanLDEHJTLP20,
title = {Self-aware Cyber-Physical Systems},
author = {Kirstie L Bellman and Christopher Landauer and Nikil D Dutt and Lukas Esterle and Andreas Herkersdorf and Axel Jantsch and Nima Taherinejad and Peter R Lewis and Marco Platzner and Kalle Tammem ä},
url = {https://dl.acm.org/doi/10.1145/3375716},
year = {2020},
date = {2020-01-01},
journal = {ACM Trans. Cyber Phys. Syst.},
volume = {4},
number = {4},
pages = {38:1--38:26},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Dutt, Nikil D; Regazzoni, Carlo S; Rinner, Bernhard; Yao, Xin Self-Awareness for Autonomous Systems Journal Article In: Proceedings of the IEEE, vol. 108, no. 7, pp. 971–975, 2020. @article{DBLP:journals/pieee/DuttRRY20,
title = {Self-Awareness for Autonomous Systems},
author = {Nikil D Dutt and Carlo S Regazzoni and Bernhard Rinner and Xin Yao},
url = {https://doi.org/10.1109/JPROC.2020.2990784},
doi = {10.1109/JPROC.2020.2990784},
year = {2020},
date = {2020-01-01},
journal = {Proceedings of the IEEE},
volume = {108},
number = {7},
pages = {971--975},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Donyanavard, Bryan; Rahmani, Amir M; Jantsch, Axel; Mutlu, Onur; Dutt, Nikil D Intelligent Management of Mobile Systems through Computational Self-Awareness Journal Article In: CoRR, vol. abs/2008.00095, 2020. @article{DBLP:journals/corr/abs-2008-00095,
title = {Intelligent Management of Mobile Systems through Computational Self-Awareness},
author = {Bryan Donyanavard and Amir M Rahmani and Axel Jantsch and Onur Mutlu and Nikil D Dutt},
url = {https://arxiv.org/abs/2008.00095},
year = {2020},
date = {2020-01-01},
journal = {CoRR},
volume = {abs/2008.00095},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Maurer, Florian; Donyanavard, Bryan; Rahmani, Amir M; Dutt, Nikil D; Herkersdorf, Andreas Emergent Control of MPSoC Operation by a Hierarchical Supervisor / Reinforcement Learning Approach Proceedings Article In: 2020 Design, Automation & Test in Europe Conference & Exhibition,
DATE 2020, Grenoble, France, March 9-13, 2020, pp. 1562–1567, IEEE, 2020. @inproceedings{DBLP:conf/date/MaurerDRDH20,
title = {Emergent Control of MPSoC Operation by a Hierarchical Supervisor / Reinforcement Learning Approach},
author = {Florian Maurer and Bryan Donyanavard and Amir M Rahmani and Nikil D Dutt and Andreas Herkersdorf},
url = {https://doi.org/10.23919/DATE48585.2020.9116574},
doi = {10.23919/DATE48585.2020.9116574},
year = {2020},
date = {2020-01-01},
booktitle = {2020 Design, Automation & Test in Europe Conference & Exhibition,
DATE 2020, Grenoble, France, March 9-13, 2020},
pages = {1562--1567},
publisher = {IEEE},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
2019
|
Rambo, Eberle A; Donyanavard, Bryan; Seo, Minjun; Maurer, Florian; Kadeed, Thawra; de Melo, Caio Batista; Maity, Biswadip; Surhonne, Anmol; Herkersdorf, Andreas; Kurdahi, Fadi J; Dutt, Nikil D; Ernst, Rolf The Information Processing Factory: Organization, Terminology, and Definitions Journal Article In: CoRR, vol. abs/1907.01578, 2019. @article{DBLP:journals/corr/abs-1907-01578,
title = {The Information Processing Factory: Organization, Terminology, and Definitions},
author = {Eberle A Rambo and Bryan Donyanavard and Minjun Seo and Florian Maurer and Thawra Kadeed and Caio Batista de Melo and Biswadip Maity and Anmol Surhonne and Andreas Herkersdorf and Fadi J Kurdahi and Nikil D Dutt and Rolf Ernst},
url = {http://arxiv.org/abs/1907.01578},
year = {2019},
date = {2019-01-01},
journal = {CoRR},
volume = {abs/1907.01578},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Rambo, Eberle A; Kadeed, Thawra; Ernst, Rolf; Seo, Minjun; Kurdahi, Fadi J; Donyanavard, Bryan; de Melo, Caio Batista; Maity, Biswadip; Moazzemi, Kasra; Stewart, Kenneth; Yi, Saehanseul; Rahmani, Amir M; Dutt, Nikil D; Maurer, Florian; Doan, Nguyen Anh Vu; Surhonne, Anmol; Wild, Thomas; Herkersdorf, Andreas The information processing factory: a paradigm for life cycle management of dependable systems Proceedings Article In: Proceedings of the International Conference on Hardware/Software Codesign
and System Synthesis Companion, CODES+ISSS 2019, part of ESWEEK
2019, New York, NY, USA, October 13-18, 2019, pp. 20:1–20:2, ACM, 2019. @inproceedings{DBLP:conf/codes/RamboKESKDMMMSY19,
title = {The information processing factory: a paradigm for life cycle management of dependable systems},
author = {Eberle A Rambo and Thawra Kadeed and Rolf Ernst and Minjun Seo and Fadi J Kurdahi and Bryan Donyanavard and Caio Batista de Melo and Biswadip Maity and Kasra Moazzemi and Kenneth Stewart and Saehanseul Yi and Amir M Rahmani and Nikil D Dutt and Florian Maurer and Nguyen Anh Vu Doan and Anmol Surhonne and Thomas Wild and Andreas Herkersdorf},
url = {https://doi.org/10.1145/3349567.3357391},
doi = {10.1145/3349567.3357391},
year = {2019},
date = {2019-01-01},
booktitle = {Proceedings of the International Conference on Hardware/Software Codesign
and System Synthesis Companion, CODES+ISSS 2019, part of ESWEEK
2019, New York, NY, USA, October 13-18, 2019},
pages = {20:1--20:2},
publisher = {ACM},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Donyanavard, Bryan; Mück, Tiago; Rahmani, Amir M; Dutt, Nikil D; Sadighi, Armin; Maurer, Florian; Herkersdorf, Andreas SOSA: Self-Optimizing Learning with Self-Adaptive Control for Hierarchical System-on-Chip Management Proceedings Article In: Proceedings of the 52nd Annual IEEE/ACM International Symposium
on Microarchitecture, MICRO 2019, Columbus, OH, USA, October 12-16,
2019, pp. 685–698, ACM, 2019. @inproceedings{DBLP:conf/micro/DonyanavardMRDS19,
title = {SOSA: Self-Optimizing Learning with Self-Adaptive Control for Hierarchical System-on-Chip Management},
author = {Bryan Donyanavard and Tiago Mück and Amir M Rahmani and Nikil D Dutt and Armin Sadighi and Florian Maurer and Andreas Herkersdorf},
url = {https://doi.org/10.1145/3352460.3358312},
doi = {10.1145/3352460.3358312},
year = {2019},
date = {2019-01-01},
booktitle = {Proceedings of the 52nd Annual IEEE/ACM International Symposium
on Microarchitecture, MICRO 2019, Columbus, OH, USA, October 12-16,
2019},
pages = {685--698},
publisher = {ACM},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Moazzemi, Kasra; Maity, Biswadip; Yi, Saehanseul; Rahmani, Amir M; Dutt, Nikil D HESSLE-FREE: Heterogeneous Systems Leveraging Fuzzy Control for Runtime Resource Management Journal Article In: ACM Trans. Embed. Comput. Syst., vol. 18, no. 5s, pp. 74:1–74:19, 2019. @article{DBLP:journals/tecs/MoazzemiMYRD19,
title = {HESSLE-FREE: Heterogeneous Systems Leveraging Fuzzy Control for Runtime Resource Management},
author = {Kasra Moazzemi and Biswadip Maity and Saehanseul Yi and Amir M Rahmani and Nikil D Dutt},
url = {https://doi.org/10.1145/3358203},
doi = {10.1145/3358203},
year = {2019},
date = {2019-01-01},
journal = {ACM Trans. Embed. Comput. Syst.},
volume = {18},
number = {5s},
pages = {74:1--74:19},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
2018
|
Moazzemi, K; Kanduri, A; Juhász, D; Miele, A; Rahmani, A M; Liljeberg, P; Jantsch, A; Dutt, N Trends in On-chip Dynamic Resource Management Proceedings Article In: 2018 21st Euromicro Conference on Digital System Design (DSD), pp. 62-69, 2018. @inproceedings{8491796,
title = {Trends in On-chip Dynamic Resource Management},
author = {K Moazzemi and A Kanduri and D Juhász and A Miele and A M Rahmani and P Liljeberg and A Jantsch and N Dutt},
doi = {10.1109/DSD.2018.00025},
year = {2018},
date = {2018-08-01},
booktitle = {2018 21st Euromicro Conference on Digital System Design (DSD)},
pages = {62-69},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Donvanavard, B; Monazzah, A M H; Dutt, N; Mück, T Exploring Hybrid Memory Caches in Chip Multiprocessors Proceedings Article In: 2018 13th International Symposium on Reconfigurable Communication-centric Systems-on-Chip (ReCoSoC), pp. 1-8, 2018. @inproceedings{8449386,
title = {Exploring Hybrid Memory Caches in Chip Multiprocessors},
author = {B Donvanavard and A M H Monazzah and N Dutt and T Mück},
doi = {10.1109/ReCoSoC.2018.8449386},
year = {2018},
date = {2018-07-01},
booktitle = {2018 13th International Symposium on Reconfigurable Communication-centric Systems-on-Chip (ReCoSoC)},
pages = {1-8},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|
Rahmani, Amir M.; Donyanavard, Bryan; Mück, Tiago; Moazzemi, Kasra; Jantsch, Axel; Mutlu, Onur; Dutt, Nikil SPECTR: Formal Supervisory Control and Coordination for Many-core Systems Resource Management Conference Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems, ACM, New York, NY, USA, 2018, ISBN: 978-1-4503-4911-6. @conference{Rahmani:2018:SFS:3173162.3173199,
title = {SPECTR: Formal Supervisory Control and Coordination for Many-core Systems Resource Management},
author = {Amir M. Rahmani and Bryan Donyanavard and Tiago Mück and Kasra Moazzemi and Axel Jantsch and Onur Mutlu and Nikil Dutt},
url = {http://doi.acm.org/10.1145/3173162.3173199, ACM
http://duttgroup.ics.uci.edu/wp-content/uploads/2018/05/SPECTR-formal-supervisory-control-for-many-core-resource-management_asplos18-lightning-talk.pptx, Lightning Talk [pptx]
http://duttgroup.ics.uci.edu/wp-content/uploads/2018/05/SPECTR-formal-supervisory-control-for-many-core-resource-management_asplos18-lightning-talk.pdf, Lightning Talk [pdf]
http://duttgroup.ics.uci.edu/wp-content/uploads/2018/05/SPECTR-formal-supervisory-control-for-many-core-resource-management_asplos18-talk.pptx, Slides [pptx]
http://duttgroup.ics.uci.edu/wp-content/uploads/2018/05/SPECTR-formal-supervisory-control-for-many-core-resource-management_asplos18-talk.pdf, Slides [pdf]
http://duttgroup.ics.uci.edu/wp-content/uploads/2018/05/SPECTR-formal-supervisory-control-for-many-core-resource-management_asplos18-poster.pptx, Poster [pptx]
http://duttgroup.ics.uci.edu/wp-content/uploads/2018/05/SPECTR-formal-supervisory-control-for-many-core-resource-management_asplos18-poster.pdf, Poster [pdf]
},
doi = {10.1145/3173162.3173199},
isbn = {978-1-4503-4911-6},
year = {2018},
date = {2018-03-27},
booktitle = {Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems},
pages = {169--183},
publisher = {ACM},
address = {New York, NY, USA},
abstract = {Resource management strategies for many-core systems need to enable sharing of resources such as power, processing cores, and memory bandwidth while coordinating the priority and significance of system- and application-level objectives at runtime in a scalable and robust manner. State-of-the-art approaches use heuristics or machine learning for resource management, but unfortunately lack formalism in providing robustness against unexpected corner cases. While recent efforts deploy classical control-theoretic approaches with some guarantees and formalism, they lack scalability and autonomy to meet changing runtime goals. We present SPECTR, a new resource management approach for many-core systems that leverages formal supervisory control theory (SCT) to combine the strengths of classical control theory with state-of-the-art heuristic approaches to efficiently meet changing runtime goals. SPECTR is a scalable and robust control architecture and a systematic design flow for hierarchical control of many-core systems. SPECTR leverages SCT techniques such as gain scheduling to allow autonomy for individual controllers. It facilitates automatic synthesis of the high-level supervisory controller and its property verification. We implement SPECTR on an Exynos platform containing ARM's big.LITTLE-based heterogeneous multi-processor (HMP) and demonstrate that SPECTR»s use of SCT is key to managing multiple interacting resources (e.g., chip power and processing cores) in the presence of competing objectives (e.g., satisfying QoS vs. power capping). The principles of SPECTR are easily applicable to any resource type and objective as long as the management problem can be modeled using dynamical systems theory (e.g., difference equations), discrete-event dynamic systems, or fuzzy dynamics.
},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Resource management strategies for many-core systems need to enable sharing of resources such as power, processing cores, and memory bandwidth while coordinating the priority and significance of system- and application-level objectives at runtime in a scalable and robust manner. State-of-the-art approaches use heuristics or machine learning for resource management, but unfortunately lack formalism in providing robustness against unexpected corner cases. While recent efforts deploy classical control-theoretic approaches with some guarantees and formalism, they lack scalability and autonomy to meet changing runtime goals. We present SPECTR, a new resource management approach for many-core systems that leverages formal supervisory control theory (SCT) to combine the strengths of classical control theory with state-of-the-art heuristic approaches to efficiently meet changing runtime goals. SPECTR is a scalable and robust control architecture and a systematic design flow for hierarchical control of many-core systems. SPECTR leverages SCT techniques such as gain scheduling to allow autonomy for individual controllers. It facilitates automatic synthesis of the high-level supervisory controller and its property verification. We implement SPECTR on an Exynos platform containing ARM's big.LITTLE-based heterogeneous multi-processor (HMP) and demonstrate that SPECTR»s use of SCT is key to managing multiple interacting resources (e.g., chip power and processing cores) in the presence of competing objectives (e.g., satisfying QoS vs. power capping). The principles of SPECTR are easily applicable to any resource type and objective as long as the management problem can be modeled using dynamical systems theory (e.g., difference equations), discrete-event dynamic systems, or fuzzy dynamics.
|
Sagdighi, Armin; Donyanavard, Bryan; Kadeed, Thawra; Moazzemi, Kasra; Mück, Tiago; Nassar, Ahmed; Rahmani, Amir M.; Wild, Thomas; Dutt, Nikil; Ernst, Rolf; Herkersdorf, Andreas; Kurdahi, Fadi Design Methodologies for Enabling Self-awareness in Autonomous Systems Conference 2018 Design, Automation Test in Europe Conference Exhibition (DATE), 2018, ISSN: 1558-1101. @conference{8342259,
title = {Design Methodologies for Enabling Self-awareness in Autonomous Systems},
author = {Armin Sagdighi and Bryan Donyanavard and Thawra Kadeed and Kasra Moazzemi and Tiago Mück and Ahmed Nassar and Amir M. Rahmani and Thomas Wild and Nikil Dutt and Rolf Ernst and Andreas Herkersdorf and Fadi Kurdahi},
url = {https://doi.org/10.23919/DATE.2018.8342259},
doi = {10.23919/DATE.2018.8342259},
issn = {1558-1101},
year = {2018},
date = {2018-03-19},
booktitle = {2018 Design, Automation Test in Europe Conference Exhibition (DATE)},
pages = {1532-1537},
abstract = {This paper deals with challenges and possible solutions for incorporating self-awareness principles in EDA design flows for autonomous systems. We present a holistic approach that enables self-awareness across the software/hardware stack, from systems-on-chip to systems-of-systems (autonomous car) contexts. We use the Information Processing Factory (IPF) metaphor as an exemplar to show how self-awareness can be achieved across multiple abstraction levels, and discuss new research challenges. The IPF approach represents a paradigm shift in platform design by envisioning the move towards a consequent platform-centric design in which the combination of self-organizing learning and formal reactive methods guarantee the applicability of such cyber-physical systems in safety-critical and high-availability applications.
},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
This paper deals with challenges and possible solutions for incorporating self-awareness principles in EDA design flows for autonomous systems. We present a holistic approach that enables self-awareness across the software/hardware stack, from systems-on-chip to systems-of-systems (autonomous car) contexts. We use the Information Processing Factory (IPF) metaphor as an exemplar to show how self-awareness can be achieved across multiple abstraction levels, and discuss new research challenges. The IPF approach represents a paradigm shift in platform design by envisioning the move towards a consequent platform-centric design in which the combination of self-organizing learning and formal reactive methods guarantee the applicability of such cyber-physical systems in safety-critical and high-availability applications.
|
Donyanavard, Bryan; Rahmani, Amir M.; Mück, Tiago; Moazzemi, Kasra; Dutt, Nikil Gain Scheduled Control for Nonlinear Power Management in CMPs Conference 2018 Design, Automation Test in Europe Conference Exhibition (DATE), 2018. @conference{8342141,
title = {Gain Scheduled Control for Nonlinear Power Management in CMPs},
author = {Bryan Donyanavard and Amir M. Rahmani and Tiago Mück and Kasra Moazzemi and Nikil Dutt},
url = {https://doi.org/10.23919/DATE.2018.8342141},
doi = {10.23919/DATE.2018.8342141},
year = {2018},
date = {2018-03-19},
booktitle = {2018 Design, Automation Test in Europe Conference Exhibition (DATE)},
pages = {921-924},
abstract = {Dynamic voltage and frequency scaling (DVFS) is a well-established technique for power management of thermal-or energy-sensitive chip multiprocessors (CMPs). In this context, linear control theoretic solutions have been successfully implemented to control the voltage-frequency knobs. However, modern CMPs with a large range of operating frequencies and multiple voltage levels display nonlinear behavior in the relationship between frequency and power. State-of-the-art linear controllers therefore under-optimize DVFS operation. We propose a Gain Scheduled Controller (GSC) for nonlinear runtime power management of CMPs that simplifies the controller implementation of systems with varying dynamic properties by utilizing an adaptive control theoretic approach in conjunction with static linear controllers. Our design improves the accuracy of the controller over a static linear controller with minimal overhead. We implement our approach on an Exynos platform containing ARM's big.LITTLE-based heterogeneous multi-processor (HMP) and demonstrate that the system's response to changes in target power is improved by 2x while operating up to 12% more efficiently for tracking accuracy.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Dynamic voltage and frequency scaling (DVFS) is a well-established technique for power management of thermal-or energy-sensitive chip multiprocessors (CMPs). In this context, linear control theoretic solutions have been successfully implemented to control the voltage-frequency knobs. However, modern CMPs with a large range of operating frequencies and multiple voltage levels display nonlinear behavior in the relationship between frequency and power. State-of-the-art linear controllers therefore under-optimize DVFS operation. We propose a Gain Scheduled Controller (GSC) for nonlinear runtime power management of CMPs that simplifies the controller implementation of systems with varying dynamic properties by utilizing an adaptive control theoretic approach in conjunction with static linear controllers. Our design improves the accuracy of the controller over a static linear controller with minimal overhead. We implement our approach on an Exynos platform containing ARM's big.LITTLE-based heterogeneous multi-processor (HMP) and demonstrate that the system's response to changes in target power is improved by 2x while operating up to 12% more efficiently for tracking accuracy. |
Hsieh, Chen-Ying; Park, Jurn-Gyu; Dutt, Nikil D; Lim, Sung-Soo MEMCOP: memory-aware co-operative power management governor for mobile games Journal Article In: Design Autom. for Emb. Sys., vol. 22, no. 1-2, pp. 95–116, 2018. @article{DBLP:journals/dafes/HsiehPDL18,
title = {MEMCOP: memory-aware co-operative power management governor for mobile games},
author = {Chen-Ying Hsieh and Jurn-Gyu Park and Nikil D Dutt and Sung-Soo Lim},
url = {https://doi.org/10.1007/s10617-018-9201-8},
doi = {10.1007/s10617-018-9201-8},
year = {2018},
date = {2018-01-01},
journal = {Design Autom. for Emb. Sys.},
volume = {22},
number = {1-2},
pages = {95--116},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
Mück, Tiago; Donyanavard, Bryan; Moazzemi, Kasra; Rahmani, Amir M; Jantsch, Axel; Dutt, Nikil D Design Methodology for Responsive and Rrobust MIMO Control of Heterogeneous Multicores Journal Article In: IEEE Trans. Multi Scale Comput. Syst., vol. 4, no. 4, pp. 944–951, 2018. @article{DBLP:journals/tmscs/MuckDMRJD18,
title = {Design Methodology for Responsive and Rrobust MIMO Control of Heterogeneous Multicores},
author = {Tiago Mück and Bryan Donyanavard and Kasra Moazzemi and Amir M Rahmani and Axel Jantsch and Nikil D Dutt},
url = {https://doi.org/10.1109/TMSCS.2018.2808524},
doi = {10.1109/TMSCS.2018.2808524},
year = {2018},
date = {2018-01-01},
journal = {IEEE Trans. Multi Scale Comput. Syst.},
volume = {4},
number = {4},
pages = {944--951},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
2017
|
Jantsch, Axel; Dutt, Nikil D Guest Editorial: Special Issue on Self-Aware Systems on Chip Journal Article In: IEEE Design & Test, vol. 34, no. 6, pp. 6–7, 2017. @article{DBLP:journals/dt/JantschD17,
title = {Guest Editorial: Special Issue on Self-Aware Systems on Chip},
author = {Axel Jantsch and Nikil D Dutt},
url = {https://doi.org/10.1109/MDAT.2017.2757445},
doi = {10.1109/MDAT.2017.2757445},
year = {2017},
date = {2017-01-01},
journal = {IEEE Design & Test},
volume = {34},
number = {6},
pages = {6--7},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
|
2016
|
Donyanavard, Bryan; Mück, Tiago; Sarma, Santanu; Dutt, Nikil D SPARTA: runtime task allocation for energy efficient heterogeneous many-cores Proceedings Article In: Proceedings of the Eleventh IEEE/ACM/IFIP International Conference
on Hardware/Software Codesign and System Synthesis, CODES 2016,
Pittsburgh, Pennsylvania, USA, October 1-7, 2016, pp. 27:1–27:10, 2016. @inproceedings{DBLP:conf/codes/DonyanavardMSD16,
title = {SPARTA: runtime task allocation for energy efficient heterogeneous many-cores},
author = {Bryan Donyanavard and Tiago Mück and Santanu Sarma and Nikil D Dutt},
url = {http://doi.acm.org/10.1145/2968456.2968459},
doi = {10.1145/2968456.2968459},
year = {2016},
date = {2016-01-01},
booktitle = {Proceedings of the Eleventh IEEE/ACM/IFIP International Conference
on Hardware/Software Codesign and System Synthesis, CODES 2016,
Pittsburgh, Pennsylvania, USA, October 1-7, 2016},
pages = {27:1--27:10},
crossref = {DBLP:conf/codes/2016},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
|